在第五周的《大數據存儲與處理》課程中,我們深入探討了MapReduce數據處理框架及其相關的存儲支持服務。作為大數據處理的核心技術之一,MapReduce以其強大的分布式計算能力和高效的海量數據處理能力,在企業級應用中占據重要地位。
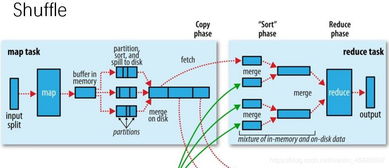
MapReduce數據處理框架基于“分而治之”的思想,將復雜的數據處理任務分解為兩個主要階段:Map階段和Reduce階段。在Map階段,原始數據被分割成多個小塊,由多個Map任務并行處理,生成中間鍵值對;在Reduce階段,系統對中間結果進行合并和匯總,最終輸出處理結果。這種架構不僅提高了數據處理效率,還具有良好的可擴展性和容錯性。
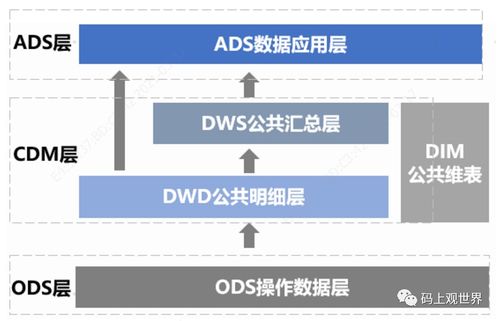
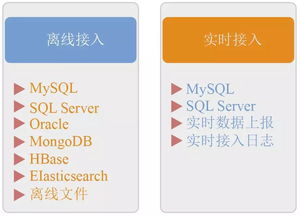
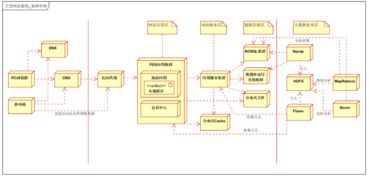
在實際應用中,MapReduce需要與多種存儲支持服務緊密配合。其中,Hadoop分布式文件系統(HDFS)是最常用的存儲基礎設施,它為MapReduce提供了高吞吐量的數據讀寫支持。HDFS通過數據分塊和副本機制,確保了數據的安全性和可用性,同時優化了數據本地化處理,減少了網絡傳輸開銷。
除了HDFS,現代大數據生態系統還提供了多種存儲支持服務,如HBase、Hive等。HBase作為分布式列式數據庫,為MapReduce提供了實時數據訪問能力;而Hive則通過類SQL的查詢語言,簡化了MapReduce程序的開發過程。這些服務與MapReduce形成了完整的數據處理鏈條,從數據存儲到計算分析,實現了端到端的大數據解決方案。
隨著技術的發展,MapReduce也在不斷演進。新一代的處理框架如Spark在內存計算方面展現出更大優勢,但MapReduce在批處理場景中仍具有不可替代的地位。掌握MapReduce及其存儲支持服務的原理與應用,對于構建高效、可靠的大數據處理平臺至關重要。
第五周的學習讓我們認識到,MapReduce不僅是一個計算模型,更是大數據生態系統中的重要組成部分。通過與各類存儲服務的協同工作,它為企業提供了處理海量數據的強大能力,為數據驅動的決策支持奠定了堅實基礎。