在當今以數(shù)據(jù)驅(qū)動的商業(yè)時代,京東作為中國領(lǐng)先的電商與科技企業(yè),其背后強大而高效的大數(shù)據(jù)技術(shù)體系是其核心競爭力之一。從海量用戶行為的實時捕捉,到復雜數(shù)據(jù)流的精準處理,再到超大規(guī)模數(shù)據(jù)的可靠存儲與智能服務,京東構(gòu)建了一套貫穿“數(shù)據(jù)采集、數(shù)據(jù)處理、數(shù)據(jù)存儲與服務支持”的全鏈路技術(shù)棧。本文將深入揭秘這一體系的核心環(huán)節(jié)與技術(shù)實踐。
一、數(shù)據(jù)采集:全域觸點的實時與批量匯聚
京東的數(shù)據(jù)采集體系旨在實現(xiàn)“全、快、準”的數(shù)據(jù)獲取。面對每日產(chǎn)生的PB級數(shù)據(jù),其采集系統(tǒng)覆蓋了用戶端、商家端、物流端及內(nèi)部系統(tǒng)等多個維度。
- 多源異構(gòu)數(shù)據(jù)接入:系統(tǒng)通過自主研發(fā)的“京東數(shù)據(jù)總線”(JDBus),統(tǒng)一對接來自App、PC網(wǎng)站、小程序、IoT設備、服務器日志、數(shù)據(jù)庫Binlog等不同源頭的數(shù)據(jù)。無論是用戶點擊、搜索、下單的實時事件流,還是商品信息、庫存變化的批量數(shù)據(jù),都能被高效捕獲。
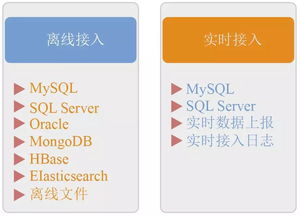
- 實時與離線雙鏈路:為了平衡即時性與成本,京東構(gòu)建了實時采集與離線采集雙通道。實時鏈路基于高性能消息隊列(如JMQ/Kafka),確保秒級延遲,支撐實時推薦、風控等場景;離線鏈路則通過分布式日志收集工具(如Flume)及定期數(shù)據(jù)同步工具,高效匯聚海量歷史數(shù)據(jù),用于深度分析與模型訓練。
- 數(shù)據(jù)質(zhì)量與安全保障:在采集端即嵌入數(shù)據(jù)校驗規(guī)則,對關(guān)鍵字段進行非空、格式、合法性校驗。通過數(shù)據(jù)脫敏、加密傳輸?shù)仁侄危瑖栏癖U嫌脩綦[私與數(shù)據(jù)安全,確保數(shù)據(jù)從源頭可信。
二、數(shù)據(jù)處理:流批一體的計算引擎與平臺化治理
采集而來的原始數(shù)據(jù)需經(jīng)過層層加工,才能轉(zhuǎn)化為有價值的洞察。京東的數(shù)據(jù)處理體系以“流批一體”為核心,兼顧時效性與準確性。
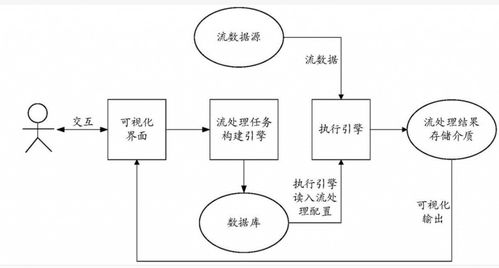
- 流式計算:實時響應業(yè)務脈搏:基于Apache Flink等引擎構(gòu)建的實時計算平臺,能夠?qū)?shù)據(jù)流進行窗口聚合、復雜事件處理(CEP)和實時ETL。例如,實時計算用戶畫像的更新、監(jiān)控物流異常、計算實時大屏指標,讓業(yè)務能夠?qū)λ蚕⑷f變的市場做出即時反應。
- 批量計算:深度挖掘數(shù)據(jù)價值:依托Hadoop、Spark等構(gòu)建的離線計算集群,處理T+1或周期性的海量數(shù)據(jù)作業(yè)。它支撐著數(shù)據(jù)倉庫(JDW)的構(gòu)建、用戶行為分析、銷量預測、供應鏈優(yōu)化等需要全局和歷史視野的復雜任務。京東通過智能資源調(diào)度與優(yōu)化,極大提升了批量作業(yè)的執(zhí)行效率。
- 數(shù)據(jù)開發(fā)與治理平臺化:為了降低技術(shù)門檻,京東內(nèi)部提供了“數(shù)坊”等一站式數(shù)據(jù)開發(fā)平臺。數(shù)據(jù)工程師和分析師可以通過可視化界面進行任務編排、依賴管理、監(jiān)控告警。建立了完善的數(shù)據(jù)資產(chǎn)目錄、數(shù)據(jù)血緣追蹤和數(shù)據(jù)質(zhì)量管理體系,確保數(shù)據(jù)處理過程可追溯、結(jié)果可信任。
三、數(shù)據(jù)處理和存儲支持服務:穩(wěn)定、高效、智能的基石
經(jīng)過處理的數(shù)據(jù)需要被妥善存儲,并能高效、靈活地服務于上層應用。京東在此環(huán)節(jié)提供了多層次、多模型的數(shù)據(jù)存儲與查詢服務。
- 分層存儲架構(gòu):根據(jù)數(shù)據(jù)的訪問頻率和成本要求,采用經(jīng)典的數(shù)據(jù)湖(Data Lake)與數(shù)據(jù)倉庫(Data Warehouse)分層架構(gòu)。
- 原始數(shù)據(jù)層:將采集的原始數(shù)據(jù)以低成本對象存儲(如HDFS、OSS)形式保存,保留數(shù)據(jù)全貌。
- 明細與匯總層:經(jīng)過清洗、整合的數(shù)據(jù),存儲在Hive、ClickHouse等系統(tǒng)中,支持靈活的交互式查詢與分析。
- 應用數(shù)據(jù)層:為特定高性能場景服務,將數(shù)據(jù)導入Redis、HBase、Elasticsearch等在線存儲,提供毫秒級讀寫,支撐商品詳情頁、訂單查詢、搜索推薦等核心業(yè)務。
- 統(tǒng)一查詢與數(shù)據(jù)服務:為了避免“數(shù)據(jù)孤島”,京東構(gòu)建了統(tǒng)一的查詢引擎(如Presto/Trino)和數(shù)據(jù)服務中間件。業(yè)務方無需關(guān)心數(shù)據(jù)物理存儲位置,通過標準SQL或API即可跨源查詢。數(shù)據(jù)服務層將數(shù)據(jù)封裝成API,穩(wěn)定、安全地提供給前端應用、算法模型和合作伙伴。
- 存儲優(yōu)化與智能運維:面對爆炸式增長的數(shù)據(jù)量,京東通過數(shù)據(jù)生命周期管理(自動冷熱分層、歸檔與刪除)、智能壓縮算法、存儲格式優(yōu)化(如ORC/Parquet)等手段持續(xù)降低成本。基于AI的智能運維系統(tǒng)對集群健康度、容量進行預測與自動擴縮容,保障存儲服務的超高可用性與穩(wěn)定性。
###
京東的大數(shù)據(jù)技術(shù)體系,是一條從數(shù)據(jù)源頭到價值終端的精密的“數(shù)據(jù)流水線”。它不僅是技術(shù)的簡單堆砌,更是業(yè)務需求、工程實踐與平臺化運營深度結(jié)合的產(chǎn)物。通過持續(xù)迭代的采集能力、強大的流批一體處理引擎以及穩(wěn)定智能的存儲服務支撐,京東確保了數(shù)據(jù)資產(chǎn)能夠被高效、可靠地轉(zhuǎn)化為驅(qū)動業(yè)務增長、優(yōu)化用戶體驗、提升運營效率的核心動能,為其在零售、物流、科技等領(lǐng)域的持續(xù)領(lǐng)先奠定了堅實的數(shù)據(jù)基石。