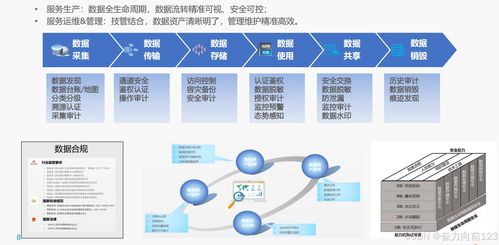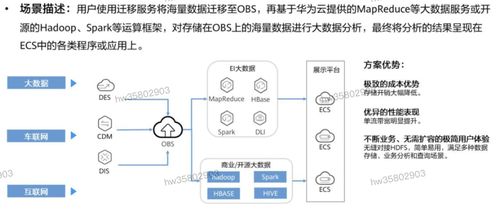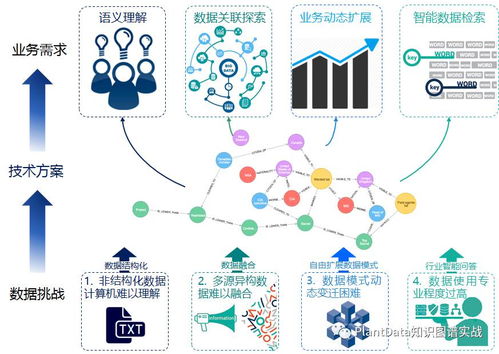
隨著數據規模的不斷增長和業務需求的實時化,大數據實時計算已成為現代數據處理架構中的核心組成部分。基于阿里云的表格存儲(Table Store)和Blink流計算引擎,企業可以實現高效、穩定的大數據實時計算解決方案。本文將探討基于表格存儲和Blink的大數據實時計算最佳實踐,涵蓋數據處理、存儲、計算流程以及優化策略,旨在為讀者提供實用的技術指導。
數據處理與存儲支持服務
表格存儲作為阿里云提供的高性能、高可擴展的NoSQL數據存儲服務,為實時計算提供了可靠的基礎。它支持海量結構化數據的存儲和訪問,具備低延遲和高吞吐的特性,適用于實時數據寫入和查詢場景。結合Blink(阿里云基于Apache Flink優化的流計算引擎),可以實現從數據采集、處理到存儲的全鏈路實時化。
在數據處理方面,Blink提供了強大的流式計算能力,包括事件時間處理、狀態管理和窗口操作。通過將表格存儲作為數據源或數據匯,Blink可以直接讀取或寫入數據,實現實時ETL、聚合分析和異常檢測。例如,在電商場景中,用戶行為數據可以實時寫入表格存儲,Blink則進行實時處理,輸出推薦結果或監控指標。
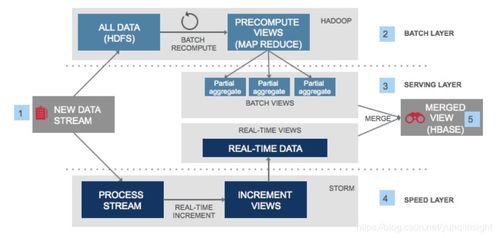
大數據實時計算架構
一個典型的基于表格存儲和Blink的實時計算架構包括以下組件:
- 數據源:如日志、傳感器數據或業務數據庫變更,通過數據采集工具(如Logstash或DataX)實時推送到表格存儲。
- 表格存儲:作為中間數據層,存儲原始數據或處理后的結果,支持高并發讀寫。
- Blink流計算引擎:從表格存儲消費數據,執行實時計算邏輯,如過濾、聚合或機器學習推理,并將結果寫回表格存儲或其他下游系統(如數據倉庫或消息隊列)。
- 數據消費:應用系統從表格存儲獲取實時結果,用于儀表盤、報警或業務決策。
這種架構的優勢在于其靈活性和擴展性。表格存儲的自動分片和負載均衡機制確保了數據存儲的穩定性,而Blink的分布式計算能力則支持水平擴展,以應對高流量場景。
最佳實踐與優化策略
實施基于表格存儲和Blink的實時計算方案時,需遵循以下最佳實踐:
- 數據模型設計:在表格存儲中,合理設計主鍵和數據分區,以優化查詢性能。例如,使用時間戳作為分區鍵,便于時間范圍查詢。
- 計算邏輯優化:在Blink作業中,利用事件時間處理和狀態后端(如RocksDB)來保證計算的準確性和容錯性。避免頻繁的狀態操作,以減少延遲。
- 資源管理:根據數據量調整Blink集群的資源分配,確保計算任務不會因資源不足而延遲。阿里云提供了監控工具,可用于實時跟蹤作業性能。
- 容錯與一致性:通過Blink的檢查點機制和表格存儲的事務支持,實現端到端的一致性。在故障恢復時,系統能夠從最近檢查點重啟,減少數據丟失。
- 成本控制:合理使用表格存儲的容量型和性能型實例,結合Blink的自動擴縮容功能,平衡性能與成本。
應用場景與案例
基于表格存儲和Blink的實時計算在多個領域有廣泛應用。例如,在金融風控中,實時處理交易數據以檢測欺詐行為;在物聯網中,分析傳感器數據以預測設備故障;在在線廣告中,實時計算用戶點擊率以優化投放策略。這些場景都得益于系統的高吞吐和低延遲特性。
總結
基于表格存儲和Blink的大數據實時計算方案提供了一種高效、可靠的數據處理路徑。通過合理的架構設計和優化策略,企業能夠快速響應業務變化,實現實時洞察。隨著技術的演進,這一方案有望在更多場景中發揮關鍵作用。讀者可參考阿里云云棲社區或CSDN博客獲取更多實踐案例和深度解析。