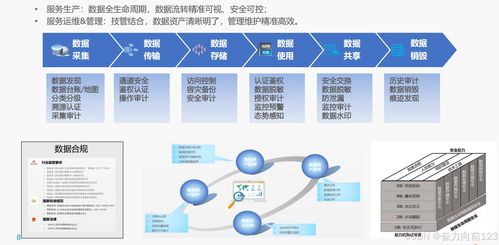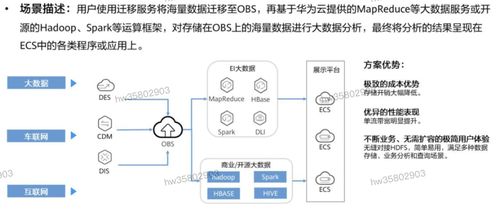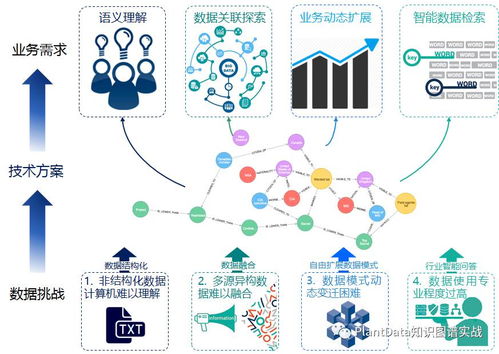
Kafka 是一個開源的分布式流處理平臺,由 LinkedIn 開發并捐贈給 Apache 軟件基金會。它被設計用于處理高吞吐量、低延遲的實時數據流,廣泛應用于大數據處理、日志收集、事件驅動架構和實時分析等領域。本文將從數據處理和存儲支持服務兩個維度,全面解析 Kafka 的核心特性和應用場景。
Kafka 數據處理能力
Kafka 的核心優勢在于其高效的數據處理機制。它采用發布-訂閱模型,允許生產者將數據發布到主題(topic),而消費者則訂閱這些主題以接收數據。這種模式支持多個消費者同時讀取同一數據流,非常適合構建松耦合的分布式系統。
數據處理的關鍵特性包括:
- 高吞吐量和低延遲:Kafka 能夠處理每秒數百萬條消息,延遲可低至毫秒級,這得益于其優化的網絡協議和批量處理機制。
- 可擴展性:通過分區(partition)機制,Kafka 可以將主題數據分布到多個代理(broker)上,實現水平擴展,輕松應對數據量增長。
- 容錯性:Kafka 使用副本(replica)機制,確保數據在節點故障時不會丟失。每個分區可以有多個副本,其中一個作為領導者(leader),其他作為追隨者(follower),自動處理故障轉移。
- 流處理集成:Kafka 與流處理框架如 Kafka Streams 和 Apache Flink 無縫集成,支持實時數據轉換、聚合和復雜事件處理。
Kafka 存儲支持服務
Kafka 不僅是一個消息隊列,還是一個持久化存儲系統。它將所有消息以日志形式持久化到磁盤,確保數據可靠性和可重放性。存儲支持服務的主要特點包括:
- 持久化存儲:Kafka 將所有消息存儲在磁盤上,并支持配置保留策略(如基于時間或大小),允許消費者按需讀取歷史數據。
- 高效數據管理:通過順序 I/O 和零拷貝技術,Kafka 優化了磁盤讀寫性能,減少了系統開銷。數據以分段(segment)形式存儲,便于管理和清理。
- 數據壓縮:Kafka 支持消息壓縮(如 gzip、snappy),減少存儲空間和網絡傳輸開銷,同時保持數據完整性。
- 連接器和生態系統:Kafka Connect 提供了與外部存儲系統(如數據庫、Hadoop、云存儲)的集成,支持數據導入和導出,擴展了存儲支持能力。
應用場景與夜夜漫筆的啟示
Kafka 的靈活性和可靠性使其在多個領域大放異彩。例如,在夜夜漫筆這樣的日志分析平臺中,Kafka 可以作為中央數據管道,收集用戶行為日志,實時處理并存儲到后端系統,用于生成洞察報告。通過 Kafka,企業能夠構建可擴展的數據處理架構,支持實時監控、推薦系統和欺詐檢測等應用。
Kafka 以其強大的數據處理和存儲支持服務,成為現代數據驅動應用的核心組件。無論您是構建實時流處理系統還是需要可靠的數據存儲解決方案,Kafka 都能提供高效、彈性的支持。