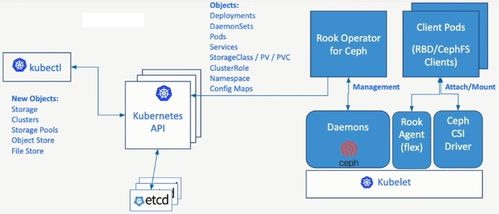
Ceph是一個開源的、高度可擴展的分布式存儲系統,其設計目標是提供高性能、高可靠性和無單點故障的存儲服務。以下是對Ceph數據處理和存儲支持服務的關鍵知識點整理:
一、Ceph架構核心組件
- RADOS(可靠自主分布式對象存儲):Ceph的核心底層存儲系統,負責數據分布、復制和故障恢復。
- MON(Monitor):維護集群狀態映射,包括OSD Map、PG Map和CRUSH Map,確保集群一致性。
- OSD(Object Storage Daemon):負責數據存儲、復制和恢復,每個OSD守護進程管理一塊物理磁盤。
- MDS(Metadata Server):僅用于CephFS,管理文件系統元數據。
二、數據處理流程
- 數據寫入過程:
- 客戶端通過CRUSH算法計算數據對象應存儲的PG(Placement Group)。
- 根據PG映射到一組OSD,實現數據的分布式存儲和冗余。
- 數據寫入采用Primary-Secondary模型,確保一致性和高可用。
- 數據讀取過程:
- 客戶端直接與Primary OSD交互獲取數據,減少延遲。
- 若Primary OSD故障,自動切換到其他OSD。
- 數據均衡與恢復:
- Ceph通過CRUSH算法動態調整數據分布,避免熱點問題。
- 當OSD故障或新增時,自動觸發數據遷移和恢復,保持數據冗余級別。
三、存儲支持服務
- 對象存儲(RADOSGW):
- 提供與AWS S3和Swift兼容的RESTful API,適用于云存儲和大規模非結構化數據。
- 支持多租戶和訪問控制。
- 塊存儲(RBD):
- 提供虛擬塊設備,支持快照、克隆和鏡像功能,適用于虛擬機存儲和數據庫。
- 與KVM、OpenStack等虛擬化平臺無縫集成。
- 文件系統存儲(CephFS):
- 提供符合POSIX標準的分布式文件系統,支持多客戶端并發訪問。
- 依賴MDS管理元數據,確保文件系統的一致性和性能。
四、數據一致性與可靠性機制
- CRUSH算法:
- 基于偽隨機分布的數據定位算法,避免中央元數據查詢瓶頸。
- 支持自定義故障域,提高數據可靠性。
- 副本與糾刪碼:
- 默認采用多副本機制(通常為3副本),確保數據冗余。
- 支持糾刪碼(Erasure Coding),在保證可靠性的同時顯著降低存儲開銷。
- 心跳與故障檢測:
- MON和OSD通過心跳機制實時監控節點狀態,快速檢測故障并觸發恢復。
五、性能優化與擴展性
- 數據分布策略:通過調整CRUSH規則優化數據分布,提升I/O性能。
- 緩存機制:支持分層存儲,結合SSD作為緩存層加速熱點數據訪問。
- 橫向擴展:通過增加OSD節點線性提升存儲容量和吞吐量,無單點瓶頸。
六、應用場景
- 云計算平臺:作為OpenStack、Kubernetes的后端存儲,提供彈性塊和對象存儲。
- 大數據分析:支持Hadoop、Spark等框架,處理海量非結構化數據。
- 備份與歸檔:利用其高可靠性和低成本特性,用于長期數據保存。
Ceph通過其分布式架構和靈活的數據處理機制,為企業級應用提供了高性能、高可靠的存儲解決方案。深入理解其核心組件、數據處理流程及存儲服務,有助于優化部署和運維實踐。